BareWave: Waveform-Native Flow-Matching Text-to-Speech
Wei Fan, Chao-Hong Tan, Qian Chen, Wen Wang, Xiangang Li, Kejiang Chen, Weiming Zhang, Nenghai Yu
Abstract Removing intermediate representations and separately trained decoding stages has become an important direction in generative modeling. In text-to-speech, however, high-quality systems are still commonly built through an intermediate acoustic representation before waveform synthesis. In this work, we present BareWave, a fully waveform-native framework for direct text-to-wave generation in flow-matching TTS. We consider this setting to raise three training challenges: raw-waveform modeling lacks a strong pretrained representational scaffold, there is no single noise schedule that remains optimal throughout training, and data-space perceptual objectives do not automatically share the temporal structure of the velocity-space flow objective. As a result, direct waveform training is hard to optimize efficiently, hard to push toward a strong final operating point with a fixed recipe, and hard to integrate effective perceptual refinement. Guided by this view, we develop a direct text-to-wave training framework that combines training-time representation alignment, staged noise scheduling, and velocity-aware perceptual alignment (VAPA), while preserving a single waveform-native inference path without pretrained components at test time. Experiments on zero-shot voice cloning show that strong intelligibility, speaker similarity, and naturalness can be achieved under a fully waveform-native inference path, supporting waveform-native flow-matching TTS as a practical direction.
Contents
This page is for research demonstration purposes only.
Model Overview
Figure 1: Comparison with Existing Methods
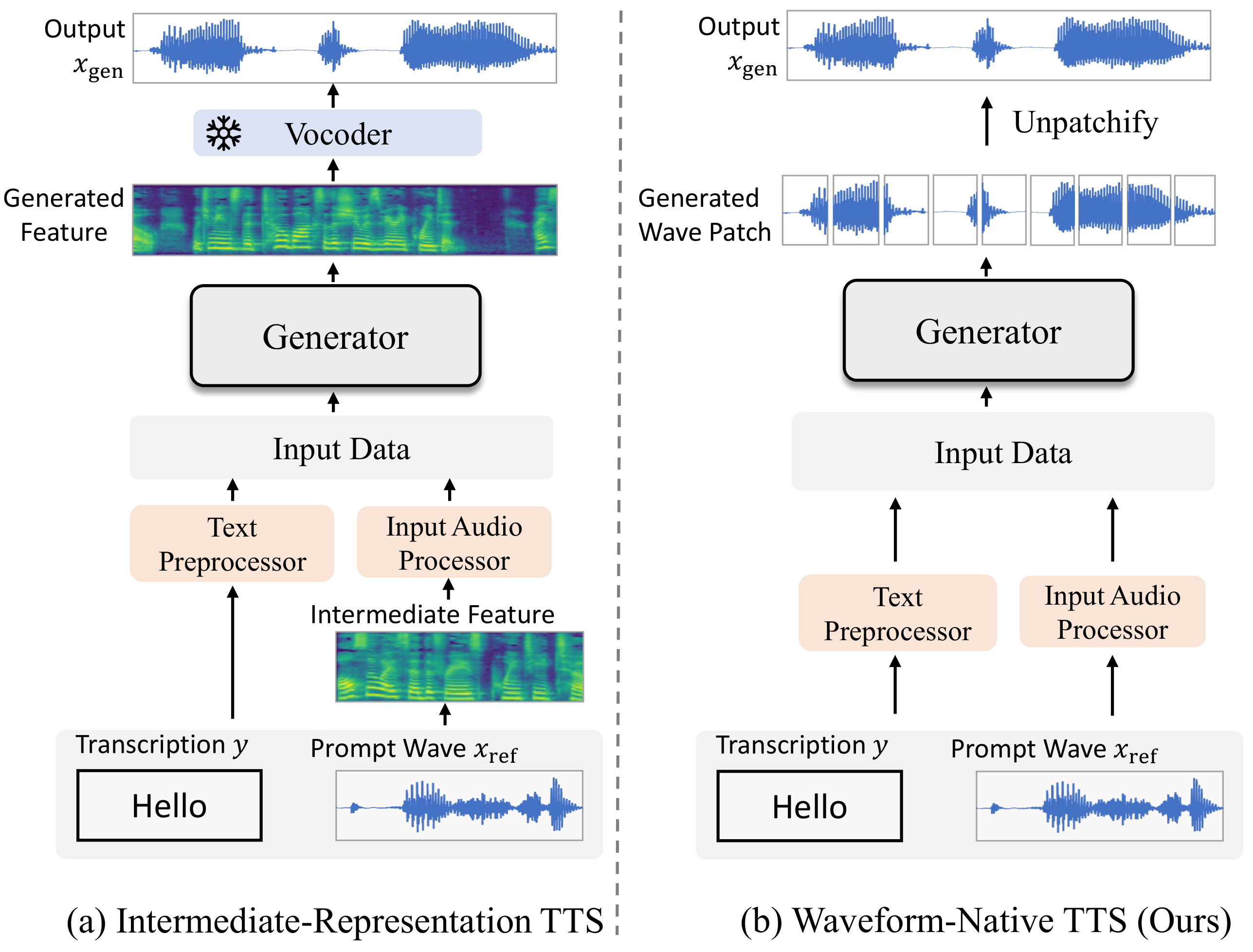
Mainstream TTS pipelines rely on intermediate representations and separate waveform decoders, whereas our framework is fully waveform-native.
Figure 2: Method Overview
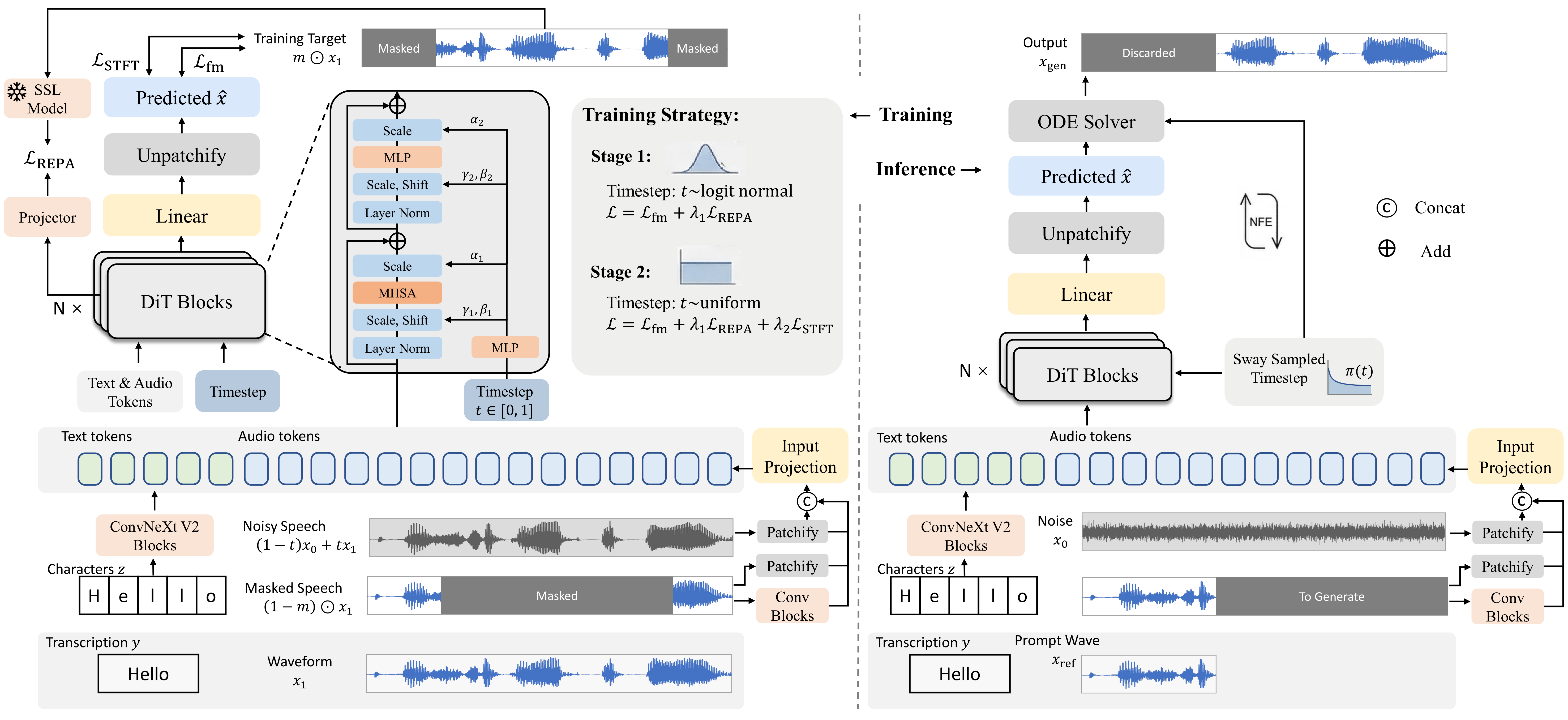
Overview of our training framework combining representation alignment, staged noise scheduling, and velocity-aware perceptual alignment.
Main Contributions
- We present BareWave, a fully waveform-native framework for zero-shot TTS, with no intermediate acoustic representation, pretrained inference-time component, or separate vocoder.
- We develop a direct text-to-wave training recipe that combines representation alignment, staged noise scheduling, and velocity-aware perceptual alignment while preserving a single waveform-native inference path.
- We observe that data-space perceptual losses are implicitly down-weighted relative to the velocity-space flow objective near cleaner timesteps, and propose Velocity-Aware Perceptual Alignment (VAPA) to match the temporal structure of the flow objective.
Audio Samples
These samples correspond to the systems compared in Table 2 of the paper under the zero-shot voice cloning setting. Both our waveform-native methods and the F5-TTS baseline are trained on the same Emilia English subset, and all samples here are drawn from LibriSpeech-PC test-clean.
Prompt is the reference audio for zero-shot cloning, and Ground Truth is the original target speech. F5-TTS (mel-based) is the strong intermediate-representation baseline. Simple direct-wave baseline is the simplest direct-wave baseline, which predicts waveform patches directly from raw waveform patch prompts. Ours (basic training) uses the same waveform-native architecture as our method, but is trained only with the basic MSE flow-matching loss under a fixed logit-normal noise schedule, without the proposed training design. Ours (proposed training scheme) is our full waveform-native system with representation alignment, staged noise scheduling, and velocity-aware perceptual alignment.
Sample 1 (1580-141083-0038)
Target Text: I understand you to say that there are three students who use this stair, and are in the habit of passing your door? Yes, there are.
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
Sample 2 (6829-68769-0015)
Target Text: Sometimes I'm that yearning for a smoke I'm nearly crazy, an' I don't know which is worst, dying one way or another.
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
Sample 3 (6829-68771-0035)
Target Text: Will you leave me alone in my own room, or must I go away to escape you?
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
Sample 4 (6930-81414-0023)
Target Text: Perchance, too, Kaffar's death might serve him in good stead.
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
Sample 5 (7127-75947-0024)
Target Text: Look yonder, do you not see the moon slowly rising, silvering the topmost branches of the chestnuts and the oaks.
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
Sample 6 (7176-88083-0002)
Target Text: His feet were red, his long narrow beak, with its saw toothed edges and sharp hooked tip, was bright red.
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
Sample 7 (8230-279154-0017)
Target Text: There may be a specific feeling which could be called the feeling of "pastness," especially where immediate memory is concerned.
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
Sample 8 (8455-210777-0014)
Target Text: Sir Kennington Oval is a very fine player, said my wife.
| Prompt | Ground Truth | F5-TTS (mel-based) |
Simple direct-wave baseline |
Ours (basic training) |
Ours (proposed training scheme) |
|---|---|---|---|---|---|
This page is for research demonstration purposes only.